
特斯拉发布 Cybercab 后,股价大跌
特斯拉在昨天洛杉矶举行的 We, Robot 产品发布会上推出了两款新车,CEO 马斯克在会上介绍了名为 Cybercab 的自动驾驶出租车和 Robovan 自动驾驶巴士,随后股价下跌超过 8%。

图源:特斯拉
Cybercab 是一款双座电动车,配备蝴蝶门和无线充电系统,但没有方向盘和踏板。特斯拉计划于 2026 年开始量产 Cybercab,售价目标低于 3 万美元,预计运营成本为每英里 20 美分。Robovan 则可作为 20 座巴士或货运车辆使用,主要针对密集城市地区。
然而,马斯克并未提供 Cybercab 和 Robovan 的技术细节,也未明确自动驾驶未来的商业化路径。投资者对 Cybercab 对此表示担忧,也反映出市场对发布会内容的失望情绪。
值得注意的是,马斯克过去曾多次预测自动驾驶技术的发展进度,但均未如期实现。
传字节跳动解雇数百名TikTok员工,转向人工智能内容审核
据外媒报道,字节跳动旗下TikTok正在裁员数百名员工,报道称,裁员主要涉及马来西亚的内容审核运营团队员工,尽管TikTok没有提供具体数字,但表示受影响人数不到500人。
此次裁员是在今年早些时候进行的一系列裁员之后进行的。4月份,字节跳动在爱尔兰裁员超过250人,5月份有消息称,该公司裁员约1000名运营和营销团队员工。1月份,TikTok解雇了60名销售和广告员工。

图源:网络
据悉,TikTok此前使用自动检测和人工审核来检查社交网络上共享的内容,但现在更倾向于自动化技术。
对于裁员消息,TikTok发言人表示:“这些改变将成为我们进一步加强内容审核全球运营模式的持续努力的一部分。我们预计仅2024年就将在全球范围内投资20亿美元用于信任和安全,并继续提高我们工作的效率,目前已经通过自动化技术删除了80%的违规内容。”
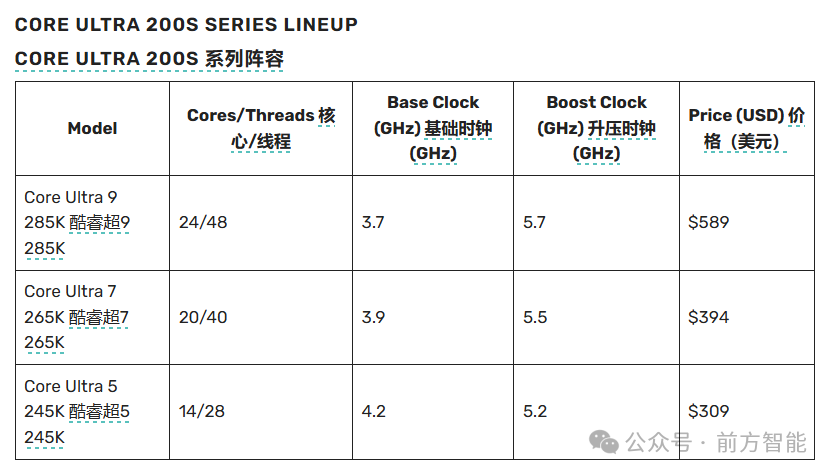
英特尔发布首款人工智能驱动的桌面处理器Core Ultra 200S系列
近日,英特尔推出Core Ultra 200S系列,这是其首款人工智能驱动的桌面处理器,将于2024年10月24日起发售,旨在增强AI PC能力。
Core Ultra 200S系列包括五种不同的型号,其中的旗舰产品是Core Ultra 9 285K。
图源:Intel
Core Ultra 200S系列配备多达8个新一代高性能核心(P核心)和多达16个高效核心(E核心),其多线程性能比前代产品高出14%,同时还显著减少能耗。该处理器在日常应用中实现了高达58%的封装功耗降低,在游戏过程中实现了高达 165W的功耗降低。
与竞争对手的旗舰处理器相比,Core Ultra 200S系列在内容创建应用程序中的AI性能提高了50%,旨在处理密集型AI任务的同时不会影响游戏或日常使用,例如优化游戏中的面部和手势跟踪,从而减轻独立GPU的AI处理负担,以优化整体系统性能。新处理器还配备了集成Xe GPU,可提高图形性能并增强媒体支持。
Core Ultra 200S系列的突出特点之一是引入了先进的超频功能。用户现在可以利用对时钟速度的细粒度控制,P核和E核的步长小至16.67 MHz。此外,新架构支持新型XMP和CUDIMM DDR5内存等内存配置,使用户能够进一步突破性能极限。
连接选项也得到了改进,包括20个PCIe 5.0通道并支持集成Thunderbolt™ 4和Wi-Fi 6E功能,确保游戏玩家和内容创作者能够高效连接到各种外围设备。多个USB 3.2端口的引入为希望同时连接各种设备的用户增加了更多灵活性。
AMD 举行 Advancing AI 活动,推出一系列 AI 芯片
2024 年 10 月 10 日,AMD 在旧金山举行的 "Advancing AI" 活动上发布了一系列新产品,涵盖 Ryzen、Instinct 和 Epyc 品牌,全面布局 AI 计算市场。

图源:AMD
主要亮点包括:
-
Ryzen AI PRO 300 系列处理器:采用 Zen 5 架构,最高可配 12 核 24 线程;集成 NPU,提供 55TOPS AI 算力;专为商用 PC 设计,支持微软 Copilot+ PC。
-
Instinct MI325X AI 加速器:配备 256GB HBM3e 显存,带宽达 6TB/s;性能号称超越 NVIDIA H200;预计 2024 年第四季度量产。
-
第五代 Epyc 处理器(代号"Turin"):最高可配 192 个 Zen 5 核心;单核频率可达 5GHz;号称性能比上代提升 2.7 倍。
-
网络产品:Pensando Pollara 400 NIC 支持Ultra Ethernet规范;Pensando Salina DPU 用于 AI 前端网络。
AMD CEO 苏姿丰预计 2028 年 AI 加速器市场规模将达 5000 亿美元。分析师则认为,AMD 在数据中心市场表现强劲,但在 AI 加速器领域仍面临英伟达的强劲竞争。新产品能否帮助 AMD 扩大市场份额,仍有待观察。
高通推出 A7 Elite 芯片,具备 40TOPS 算力的 Wi-Fi 芯片
高通近日发布了 Networking Pro A7 Elite,这是一款用于路由器和其他提供 Wi-Fi 连接的网络设备的新型芯片。A7 Elite 芯片基于今年早些时候推出的新版 Wi-Fi 标准 Wi-Fi 7,支持高达 33 GB/s 的无线带宽,并集成了 AI 协处理器,算力可达 40 TOPS。值得注意的是,A7 Elite 可管理多达 16 个数据流,这是 Wi-Fi 7 支持的最大数量。

图源:高通
A7 Elite 芯片集成了从宽带到天线的多个关键元素,包括 10G 光纤、5G、以太网、RF 前端模块和滤波器。它配备了 RF 前端子系统,能够去除天线接收到的数据载波无线信号中的干扰,进一步提高了无线连接的可靠性。芯片内置的 AI 协处理器支持本地运行 AI 模型,相比云端处理提供了更低的延迟,为各种智能应用场景铺平了道路。
高通对 A7 Elite 的应用前景充满信心。他们设想硬件制造商可以将 A7 Elite 的协处理器应用于多种创新场景。例如,可以构建能够检测恶意网络流量的智能路由器,利用神经网络自动排除技术问题,优化设备功耗,甚至执行更复杂的网络管理任务。
为了简化网络设备制造商的软件开发过程,高通提供了 100 个预优化的 AI 模型库。如果这些现成的模型无法完全满足企业的特定需求,开发者还可以在 A7 Elite 的协处理器上运行自定义软件。高通还推出了 AI Stack 软件工具包,旨在简化外部神经网络在其芯片上的优化过程。
黄仁勋将出席 CES 2025,或发布 RTX 5090
据科技媒体 The Verge 报道,英伟达的首席执行官黄仁勋将于 2025 年 1 月 6 日在拉斯维加斯举行的国际消费电子展(CES)上发表主题演讲。有消息人士透露,此次演讲会公布更多关于 RTX 50 系列的信息。

图源:Getty
黄仁勋此次将作为 CES 2025 展会的官方特邀主题演讲嘉宾,这与去年英伟达在 CES 2024 上独立举办的 "特别演讲" 流媒体活动形成鲜明对比。
近期关于英伟达新一代显卡的传闻甚嚣尘上。据悉,RTX 5090 将基于 GB202 图形处理器,搭载 21,760 个 CUDA 核心,配备 32GB GDDR7 显存,内存总线为 512 位。值得注意的是,该卡的总图形功耗(TGP)可能高达 600W,比上一代 RTX 4090 的 450W 再度提升。
自 2022 年 9 月英伟达发布 RTX 40 系列 GPU 以来,时间已经过去了两年多,因此业界普遍认为新一代显卡的发布时间已经临近。
随着 CES 2025 的临近,科技爱好者和游戏玩家都在热切期待英伟达可能带来的新产品和技术突破。无论是 AI 领域的创新还是游戏显卡的升级,黄仁勋的主题演讲都将是明年 CES 展会上最受关注的事件之一。
Inflection AI放弃Nvidia GPU,选择与英特尔合作开发新的LLM设备
日前,Inflection AI透露其最新的用于运行大型语言模型的设备将放弃Nvidia GPU,转而使用英特尔的Gaudi 3加速器。该设备是新产品Inflection for Enterprise的一部分,可提供包括基于云的人工智能服务。

图源:网络
该设备由今年4月份推出的Gaudi 3机器学习加速器提供支持,其AI优化核心数量是其前身的三倍多,与Nvidia的H100相比,英特尔的Gaudi 3也相对更便宜。Gaudi 3加速器拥有128 GB HBM2e内存,可实现3.7 Tbps的带宽和1,835 teraFLOPS的密集FP8或BF16性能。
英特尔曾透露,配备8个加速器的单一Gaudi 3系统仅需125,000美元,约为同等H100系统的三分之二。Inflection for Enterprise设备将Gaudi 3与Inflection AI最新的LLM Inflection 3.0相结合,与当前的竞争产品相比,运行成本效率提高了2倍。
英特尔和Inflection AI计划于2025年第一季度推出其联合开发的设备,英特尔将成为首批客户之一。同时,Inflection for Enterprise也可通过英特尔Tiber AI Cloud获得,该云平台提供对Gaudi 3和英特尔其他几种处理器的按需访问。
据悉,Inflection AI于2022年起步,并筹集了13亿美元用于开发名为Pi的ChatGPT替代品。今年三月,微软公司聘请了该公司联合创始人兼首席执行官 Mustafa Suleyman来领导其消费者人工智能团队,同时还招募了Inflection AI的大部分员工,并授权使用其人工智能模型,据报道,这笔交易价值6.5亿美元。
富士康与英伟达展开合作,将建立全球最大的英伟达芯片制造工厂
台湾电子代工巨头富士康(Foxconn)与英伟达宣布深化战略合作,在 AI 超级计算和芯片制造领域展开多项重大项目。

图源:网络
首先,富士康将在墨西哥建立全球最大的英伟达 GB200 超级芯片制造工厂。GB200 是英伟达新一代 Blackwell 系列计算平台的关键组件。富士康仅表示墨西哥工厂的产能将"非常非常庞大",但未透露具体细节。
其次,双方将在台湾共同打造当地最强大的 AI 超级计算机。这台超级计算机将部署在鸿海高雄超级计算中心,基于英伟达的 Blackwell 架构,预计将提供超过 90 exaFLOPS 的 AI 计算能力。系统将配备 2,000 多张 GB200 图形卡,支持高达 130 TBps 的通信带宽。
该超级计算机项目预计将于 2025 年开始部署,2026 年全面投入运营。它将支持智能制造、医疗保健、机器人和自动驾驶等多个行业的 AI 应用。
AI初创公司在2024年第三季度总融资额已达到118亿美元
据分析公司Stocklytics近日最新编制的数据显示,人工智能初创公司在过去90天内筹集了118亿美元,占2024年第三季度风险投资总额的30%。
数据表明,尽管投资者对人工智能初创公司变得更加挑剔,但他们的总体兴趣仍然强劲。Stocklytics分析师Neil Roarty指出,除去2024年第二季度筹集的创纪录的296亿美元,三季度118亿美元的新资本投入接近2023年和2024年的季度数字。但交易数量有所下降,交易总数下降了28笔,第三季度同比增长率从2023年同期的110%降至79%。
截至目前,投资者今年已向人工智能领域注入了近530亿美元,比2023年前三季度增加了35%。值得注意的交易包括OpenAI最近的66亿美元融资,公司估值为1570亿美元。从本季度的数据来看,人工智能领域的累计融资金额现已超过2410亿美元,其中美国公司筹集了近65%,即1550亿美元。亚洲人工智能初创公司已筹集530亿美元,而欧洲人工智能公司已筹集302亿美元。
OpenAI 宣布全球扩张计划,新加坡成为亚太区总部
OpenAI 今日公布了一系列重大扩张计划。该公司将在全球多个城市开设新的办事处,包括纽约、西雅图、巴黎、布鲁塞尔和新加坡,以补充其现有的旧金山、伦敦、都柏林和东京办公室。

图源:X
值得注意的是,新加坡被选为 OpenAI 的亚太区总部,预计将于今年年底开始投入使用。这个新设立的办事处将致力于支持亚太地区的客户和合作伙伴,并专注于与政府和企业建立合作关系。为推动国际业务发展,OpenAI 任命 Oliver Jay 为国际业务董事总经理,负责领导新加坡业务并监督公司的国际运营和全球扩张。
在本地化方面,OpenAI 将与新加坡 AI 展开合作,旨在扩大其 AI 技术在东南亚的应用。OpenAI 还计划投入更多资源用于开发,包括开放数据集,以确保 AI 模型更适合东南亚多样化的语言和文化。
OpenAI 表示,新加坡是全球人均 ChatGPT 使用率最高的国家之一,自今年年初以来,新加坡的每周活跃用户数量已翻倍。为支持业务增长,OpenAI 已开始在新加坡组建团队,目前正在招聘工程师。预计到年底将招聘 5 至 10 个职位,以支持技术、全球事务、运营和通信需求。
这一扩张计划紧随 OpenAI 66 亿美元融资轮、重组计划公告以及一系列高管离职之后。
人工智能先驱约翰·霍普菲尔德和杰弗里·辛顿获2024年诺贝尔物理学奖
两位被认为奠定了“当今强大机器学习基础”的科学家,多伦多大学名誉教授杰弗里·辛顿(Geoffrey Hinton)和普林斯顿大学教授约翰·霍普菲尔德(John Hopfield)被授予2024年诺贝尔物理学奖。

图源:网络
瑞典皇家科学院表示,他们的发现和发明为人工智能领域最近的许多突破奠定了基础,自20世纪80年代以来,他们的工作使得人工神经网络、松散模仿大脑结构的计算机架构的创建成为可能。
通过模仿我们大脑的连接方式,神经网络允许人工智能工具本质上“通过实例学习”。开发人员可以通过向人工神经网络提供数据来训练其识别复杂模式,从而巩固当今人工智能的一些最引人注目的用途,从语言生成到图像识别。
瑞典皇家科学院认可了辛顿等人于20世纪80年代开发的玻尔兹曼机(一种生成模型),而辛顿的工作建立在获奖者霍普菲尔德提出的霍普菲尔德网络的基础上。在2000年代,辛顿等人使用玻尔兹曼机逐层训练多层网络,后在预训练网络之上使用另一种微调算法来进一步调整权重,多层网络被重新命名为深度网络,并开启了深度学习革命。
因为在深度学习领域的成就,辛顿也被称为“人工智能教父”。去年,辛顿曾公开表示“对他一生的工作感到后悔”。据悉,辛顿于2023年辞去了谷歌的职位,以便能够引起人们对他所促成的技术所带来的潜在风险的关注。
英伟达向 OpenAI 交付首批工程版本 DGX B200,推理性能提升 15 倍
英伟达在今年 3 月份举办的 GTC 大会上正式发布了其最新的 AI 平台 DGX B200,当时英伟达给出的出货时间表则是今年晚些时候。如今 DGX B200 首批工程版本已经来到了 OpenAI 手中,OpenAI 团队也在社交媒体上放出了成员与 DGX B200 的合影。

图源:OpenAI
DGX B200 配备 8 个 Blackwell GPU,GPU 显存总计达到 1440GB,其性能为 72 petaFLOPS(训练)和 144 petaFLOPS(推理),最大功耗约为 14.3kW,采用第五代 NVIDIA NVLink 互连技术。相比前代产品,DGX B200 在训练性能上提升了 3 倍,推理性能提升了 15 倍。
英伟达表示,DGX B200 将成为 NVIDIA DGX BasePOD 和 NVIDIA DGX SuperPOD 的基础,为各种工作负载提供领先的性能。
随着工程样机的交付,业界期待 DGX B200 将如何重塑 AI 计算格局,并为未来的技术创新铺平道路。
Matterport推出可修改的3D数字孪生房产装潢展示AI工具
日前,专注于创建建筑物3D模型的技术公司Matterport推出了一款名为“Defurnish”的工具,可在人工智能驱动下,允许使用者删除房屋展示照片中不适合或反映空间不佳的物品。
Defurnish旨在解决房屋卖家和代理商面临的房屋杂乱问题。利用该工具,使用者只需单击一下,就可以一键清除不适合展示的家具,将杂乱的客厅或凌乱的车库变成干净、开放的空间。

图源:Matterport
同时,Matterport还推出了AI驱动的属性描述工具,可以利用Matterport的建筑内部空间数据底层平台智能生成书面描述。
此外,Matterport还推出了另外三种房地产科技工具。其中一个允许建筑公司合并大型项目的多个数字孪生模型,另一个允许用户在建筑工地3D扫描过程中实时“标记”,第三个一键账单处理则提供自动发票和计费功能。
Matterport董事长兼首席执行官RJ Pittman在一份声明中表示,“我们的2024年秋季版本使用户能够释放Matterport的全部潜力,想象一下,仅使用数字孪生中的数据,就能一键布置房屋或自动生成令人惊叹的房产描述。
“这些工具可以为每个人(从房地产经纪人到承包商和企业团队)节省时间、提升列表质量并简化复杂的工作流程。借助3D模型合并、字段标签和一键账单处理等功能,我们正在帮助客户以前所未有的速度、效率和精度大规模管理空间。”








