
今天,DeepSeek 团队再度引发行业关注,一篇梁文锋等多位核心成员署名的新论文《Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures》正式发布。该论文不仅系统总结了 DeepSeek-V3 在大模型训练与推理上的关键技术突破,更深入探讨了软硬件协同设计如何突破算力、内存、带宽等核心瓶颈,为下一代 AI 基础设施指明了方向。

图源:DeepSeek
背景:大模型时代的硬件瓶颈与创新契机
自 2023 年以来,大语言模型(LLM)进入爆发期。GPT-4o、LLaMa-3、Claude-3.5 Sonnet、Grok-2、Qwen2.5、Gemini-2 以及 DeepSeek-V3 等一系列旗舰产品不断刷新性能纪录。随着模型规模与数据量的激增,训练与推理的硬件成本、能耗压力和扩展性挑战日益突出。传统的“堆算力”模式逐渐难以为继,软硬件协同创新成为行业共识。
DeepSeek 团队正是在这一背景下,提出了“硬件感知模型协同设计”理念,力图在有限资源下实现大模型的极致效率与公平竞争。DeepSeek-V3 的诞生,是这一理念的集大成者。
DeepSeek-V3 的基础架构与核心创新
论文指出,DeepSeek-V3 的设计目标,是在 2048 块 NVIDIA H800 GPU 上,以远低于传统方案的成本,实现媲美超大规模集群的训练与推理能力。为此,团队围绕模型架构、低精度计算、内存优化、通信网络、推理加速等多个层面,展开了系统性创新。
图源:DeepSeek
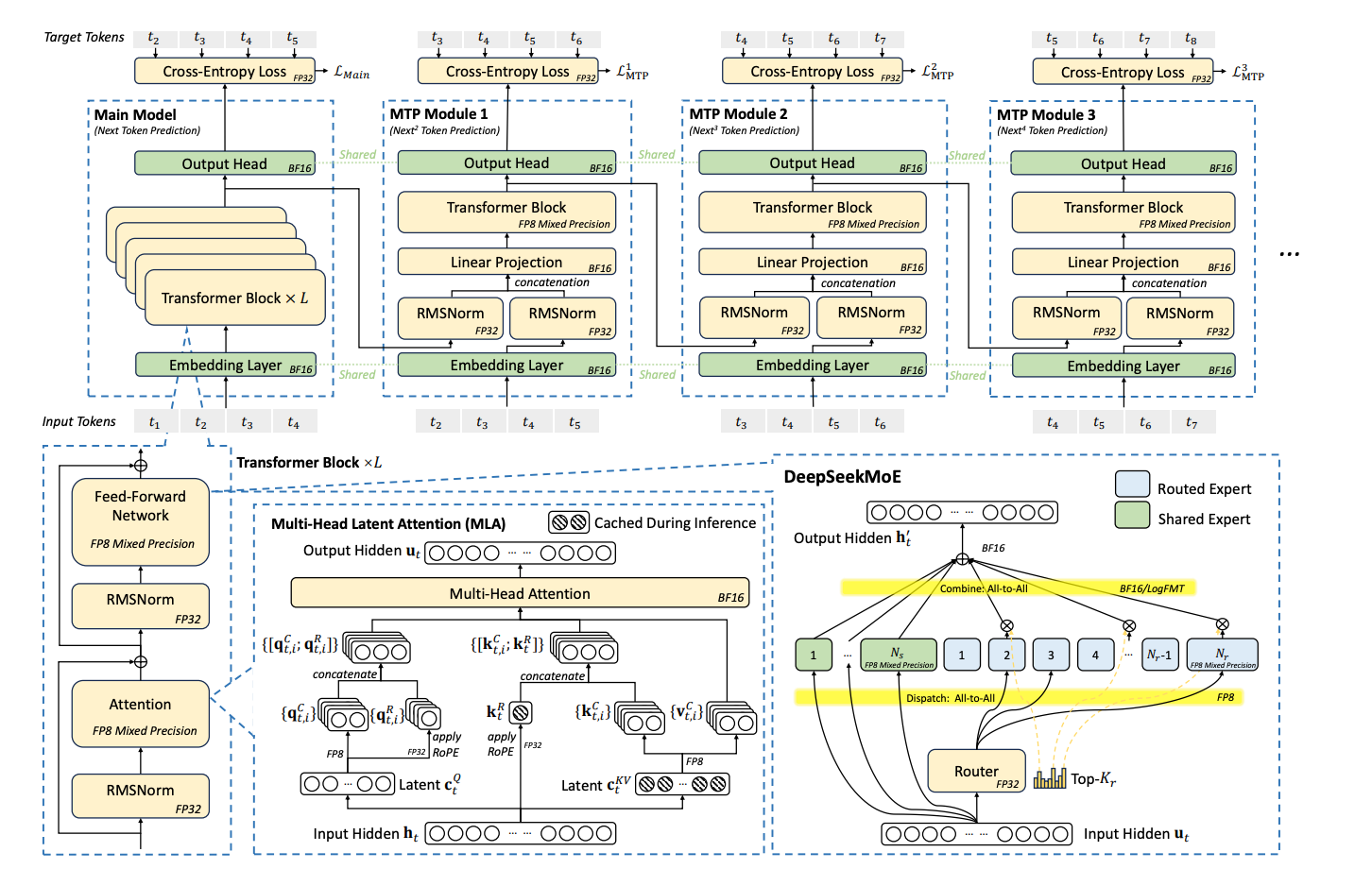
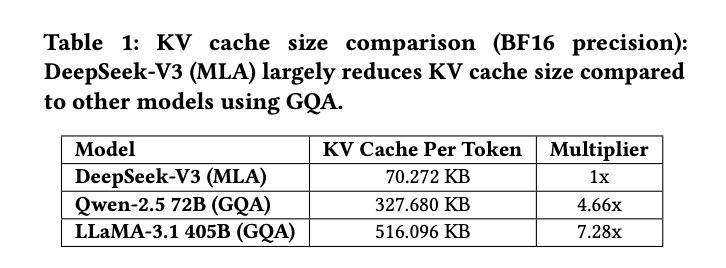
首先,DeepSeek-V3 采用了多头潜在注意力(MLA)和混合专家(MoE)两大核心架构。MLA 通过投影矩阵将所有注意力头的键值(KV)表示压缩为更小的潜在向量,只需缓存潜在向量即可,大幅降低 KV 缓存的显存占用。相比同类模型,DeepSeek-V3 每个 token 的 KV 缓存仅需 70 KB,是 LLaMA-3.1 的 1/7,Qwen-2.5 的 1/4,极大缓解了长文本推理和多轮对话下的显存瓶颈。
图源:DeepSeek
MoE 架构则通过“按需激活专家参数”,让模型总参数量可以指数级扩展,而每次计算只涉及少量专家。以 DeepSeek-V3 为例,总参数高达 6710 亿,但每 token 仅激活 370 亿参数,训练成本仅为同规模稠密模型的 1/10。得益于 MoE 的稀疏性,DeepSeek-V3 在消费级 GPU 上也能实现近 20 tokens/s 的推理速度,为个人和中小企业本地部署大模型提供了现实可能。
其次,DeepSeek-V3 在低精度计算方面首创性地引入了 FP8 混合精度训练。相比主流的 BF16,FP8 可将内存占用和计算量再减半,同时通过精细量化策略,确保精度损失低于 0.25%。这不仅极大提升了训练效率,也为低成本大模型训练树立了新标杆。
通信与网络优化:突破带宽与延迟瓶颈
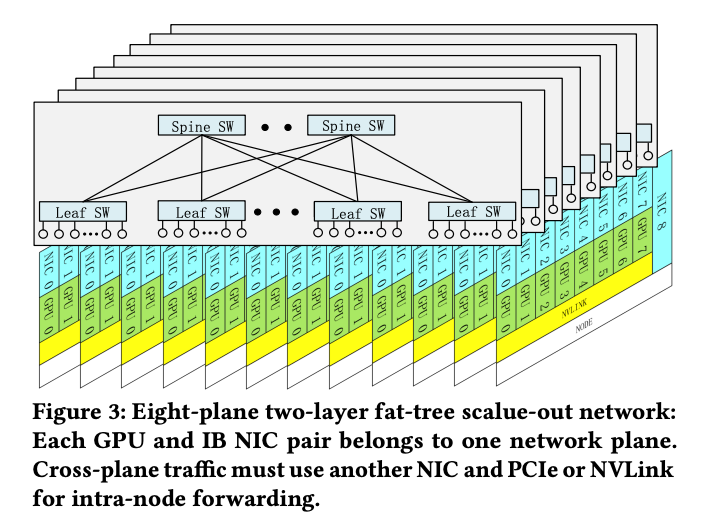
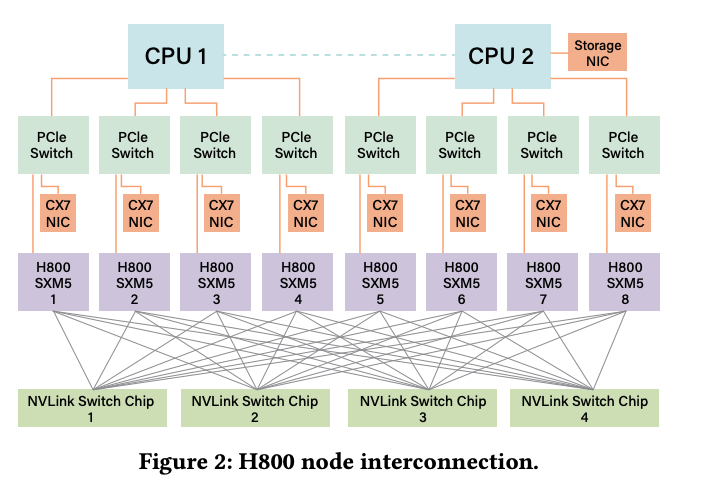
在大模型分布式训练中,通信带宽和延迟始终是性能瓶颈。DeepSeek-V3 针对 H800 GPU 节点内外带宽差异,提出了节点受限路由策略。具体做法是将 256 个专家分为 8 组,每组部署在同一节点,确保每个 token 最多只需跨 4 个节点通信。这样可充分利用 NVLink 节点内高带宽,减少跨节点 InfiniBand 通信压力,提升整体带宽利用率。
图源:DeepSeek
此外,DeepSeek-V3 部署了多平面两层胖树(MPFT)网络拓扑,每个 GPU-网卡对分配到独立的网络平面,实现流量隔离和故障隔离。MPFT 支持上万 GPU 的扩展,成本比传统三层网络降低 40%,延迟减少 30%。实测表明,MPFT 在 all-to-all 通信和专家并行场景下,与单平面多轨网络性能几乎一致,极大提升了大规模分布式训练的可扩展性与鲁棒性。
为进一步降低通信延迟,DeepSeek-V3 采用了 InfiniBand GPUDirect Async 技术,让 GPU 直接管理网络控制平面,绕过 CPU,减少数据包处理延迟。论文还建议未来硬件应原生支持多平面、低延迟、智能路由等特性,推动以太网 RDMA(RoCE)向更高性能演进。
推理加速与多 token 预测:提升用户体验
推理速度是大模型实际应用中的关键指标。DeepSeek-V3 在架构上采用了双微批重叠(dual micro-batch overlap),将 MLA 和 MoE 的计算与通信解耦为两个阶段,实现流水线并行,最大化 GPU 利用率。生产环境下,团队还采用预填充-解码分离架构,将大批量预填充和延迟敏感的解码请求分配给不同的专家并行组,进一步提升系统吞吐量。
更具突破性的是,DeepSeek-V3 引入了多 token 预测(MTP)模块。传统自回归模型每步只生成一个 token,存在序列瓶颈。MTP 允许模型以较低成本并行预测多个候选 token,并实时验证最优结果。实测显示,MTP 可将生成速度提升 1.8 倍,准确率保持在 80%-90%。通过增加每步推理的 batch size,MTP 也进一步提升了专家并行的计算强度和硬件利用率。
低精度驱动设计与 LogFMT 创新
在低精度训练和通信方面,DeepSeek-V3 不仅采用了 FP8,还探索了 LogFMT(对数浮点格式)等新型数据类型。在网络通信中,EP 并行阶段使用 FP8 量化,通信量减少 50%。团队还尝试将 LogFMT 集成到网络硬件,实现更高的信息熵密度和带宽利用率。虽然目前受限于硬件算力和带宽,LogFMT 尚未大规模应用,但其理论潜力为未来硬件设计提供了重要参考。
图源:DeepSeek
论文建议,未来硬件应原生支持低精度计算与压缩,提升累加寄存器精度,支持本地细粒度量化,让张量核心直接完成量化与反量化,减少数据搬运和带宽消耗。NVIDIA Blackwell 架构对 microscaling 数据格式的支持,正是业界向这一方向演进的典型例证。
面向未来的 AI 基础设施六大升级方向
DeepSeek 团队不仅总结了 V3 的技术突破,更结合实际部署经验,对下一代 AI 硬件架构提出了六大前瞻性建议:
首先是稳定性优先。大规模训练中,网络闪断、GPU 故障、内存静默错误等风险高企。团队建议硬件集成超越传统 ECC 的高级错误检测机制,如校验和验证、硬件冗余校验,并为终端用户提供全面的诊断工具包,实现全生命周期的数据完整性验证。
第二,颠覆互连架构。当前 CPU-GPU 之间的 PCIe 接口已成带宽瓶颈,未来应采用 NVLink、Infinity Fabric 等直连方案,或将 CPU、GPU 集成到同一扩展域,消除节点内瓶颈。高带宽内存和高主频 CPU 也是保障系统吞吐的关键。
第三,智能网络升级。未来网络需同时具备低延迟和智能感知能力。集成硅光子学实现高带宽、低能耗,基于信用的流控机制确保无损传输,自适应路由动态分配流量,容错协议提升系统鲁棒性,动态资源管理优化多任务调度。
第四,通信顺序硬件化。节点间通信应由硬件原生保证顺序一致性,减少软件层的同步和延迟。论文提出区域获取/释放机制(RAR),由硬件维护内存区域状态,实现高效排序和有序数据交付。
第五,网络计算融合。MoE 的分发与合并阶段,建议在网络硬件中集成自动分组复制、硬件级归约、LogFMT 压缩等功能,释放网络带宽潜力,提升通信效率。
第六,内存架构重构。模型规模指数级增长,内存带宽成为新瓶颈。团队建议采用 3D 堆叠 DRAM、晶圆级集成(SoW)等新技术,最大化内存带宽与计算密度,满足超大模型的需求。
产业影响与未来展望
DeepSeek-V3 的发布,不仅是技术层面的突破,更为 AI 产业生态带来了深远影响。首先,它证明了通过软硬件协同创新,中小团队也能以有限资源实现顶级大模型训练与推理,打破了超大规模集群的技术垄断。其次,论文提出的多项前瞻性建议,为硬件厂商、云服务商、AI 平台开发者提供了可落地的设计蓝图。
展望未来,随着 AI 模型持续扩展,软硬件协同将成为行业主旋律。DeepSeek-V3 的实践证明,只有将硬件特性深度融入模型设计,并反向推动硬件升级,才能实现大模型的高效可扩展与经济可持续。无论是 AI 芯片、分布式系统,还是推理引擎与基础设施,唯有打破软硬件壁垒,才能驱动 AI 产业迈向下一个高峰。
结尾
DeepSeek-V3 以极致的工程创新,打破了大模型训练与推理的成本、效率与扩展性瓶颈,为 AI 软硬件协同发展树立了新范式。无论是 MLA、MoE、FP8、MTP 等架构创新,还是多平面网络、节点受限路由、低精度通信等系统突破,都为行业提供了宝贵经验。更重要的是,DeepSeek 团队以开放、前瞻的视角,推动了 AI 基础设施的持续进化。未来,随着这些创新理念的普及与落地,AI 大模型将真正走向普惠与高效,赋能千行百业,开启智能时代的新篇章。








