
市场对英伟达 AI 芯片的需求持续旺盛,在这样的背景下,上周五英伟达股价上涨 2.2%,市值一度达到 3.53 万亿美元,短暂超越苹果(3.52 万亿美元)成为全球最有价值的公司。
但随着 AI 逐步普及,以及市场不断扩大,新的竞争者也开始崭露头角,不让英伟达独占鳌头。其中来自美国加州的 AI 芯片初创公司Cerebras Systems的表现格外亮眼,其最新发布的推理服务再次实现性能突破,让业界为之侧目。
硅谷新贵打造最强 AI 芯片

图源:Cerebras
虽然我们之前也曾介绍过 Cerebras Systems 这家公司推出的 WSE-3 处理器,但这家初创公司知名度还是太低,我们不妨再介绍一次。
Cerebras Systems 成立于 2016 年,由Andrew Feldman和 Gary Lauterbach 共同创立,两人分别担任公司 CEO 和 CTO。尽管成立时间不长,但公司已获得了包括阿布扎比增长基金(Abu Dhabi Growth Fund)、OpenAI CEO Sam Altman、AMD 前 CTO Fred Weber 等知名机构和个人的投资支持。

图源:Cerebras
Cerebras 最引人注目的创新在于其独特的 Wafer-Scale Engine(WSE)芯片设计。最新的 WSE-3 处理器采用 5 纳米工艺制造,其规格令人惊叹:
-
超过 4 万亿个晶体管
-
90 万个计算核心
-
44GB 片上 SRAM 内存
-
支持高达 1.2PB 的片外内存

图源:Cerebras
与行业标杆英伟达 H100 相比,WSE-3 在多个关键指标上都实现了质的飞跃:
-
片上内存容量是 H100 的 880 倍
-
内存带宽是 H100 的 7000 倍
-
核心数量是 H100 的 52 倍
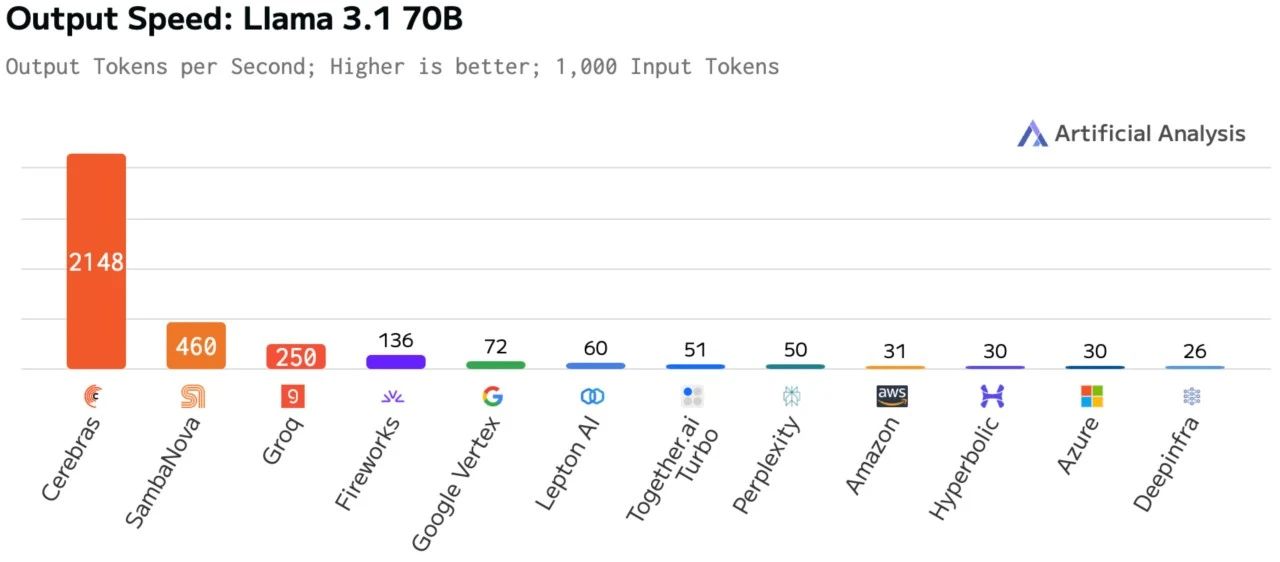
性能一骑绝尘,每秒 2100Tokens
在最新的性能更新中,Cerebras 的推理速度又一次向前迈了一大步,取得了惊人的进步。Cerebras 官方在公告中直言,这就是他们推出 Cerebras Inference 以来最大的一次更新。
当我们还在以每秒几十或者几百 tokens 的速度来衡量推理速度的时候,Cerebras 则是一步到位,将 Llama 3.1 70B 模型的推理速度推到了 2100 tokens/s 的高度,这比 WSE-3 诞生之初测试出来的 450 tokens/s 的速度提升了约 4.6 倍。
图源:Cerebras
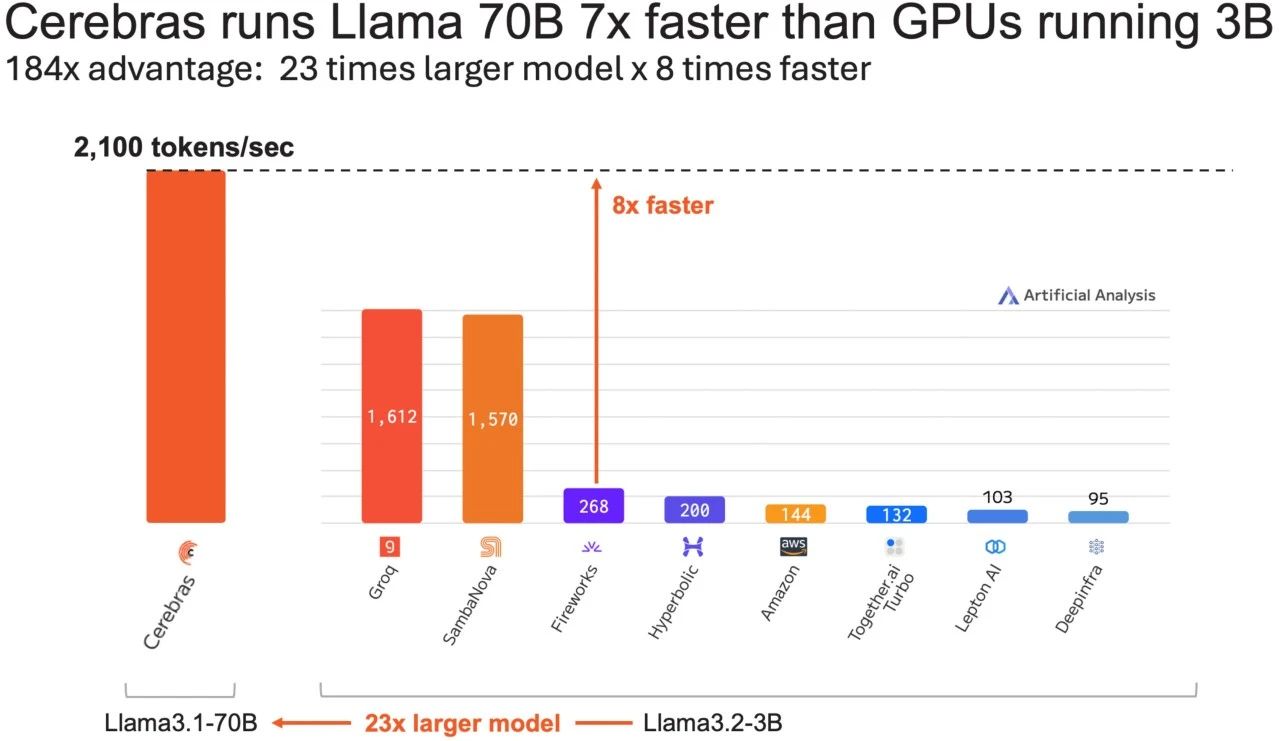
为了便于理解,这一性能比目前行业最快的 GPU 解决方案还要快 16 倍。在同样的方案下,后者跑一个模型体积比 Llama 3.1 70B(700 亿参数) 小 23 倍的 Llama3.1-3B(30 亿参数),Cerebras 依然可以比 GPU 解决方案快 8 倍。
图源:Cerebras
如果不跟行业最快的 GPU 解决方案比较,而是与主流的云服务相比,Cerebras 更是快了 68 倍之多。
如果将人类的阅读速度换算成 AI 的推理速度,那人类的平均阅读速度其实不到 10 tokens/s,2100 tokens/s 远远超出了阅读的需求,如此快速的推理速度也给 AI 发展解锁了新的可能性。未来的实时语音、实时视频相关的 AI 技术都需要更加高速的推理速度才能让用户获得更好的体验,这也是目前技术难以实现的一点。
图源:Cerebras
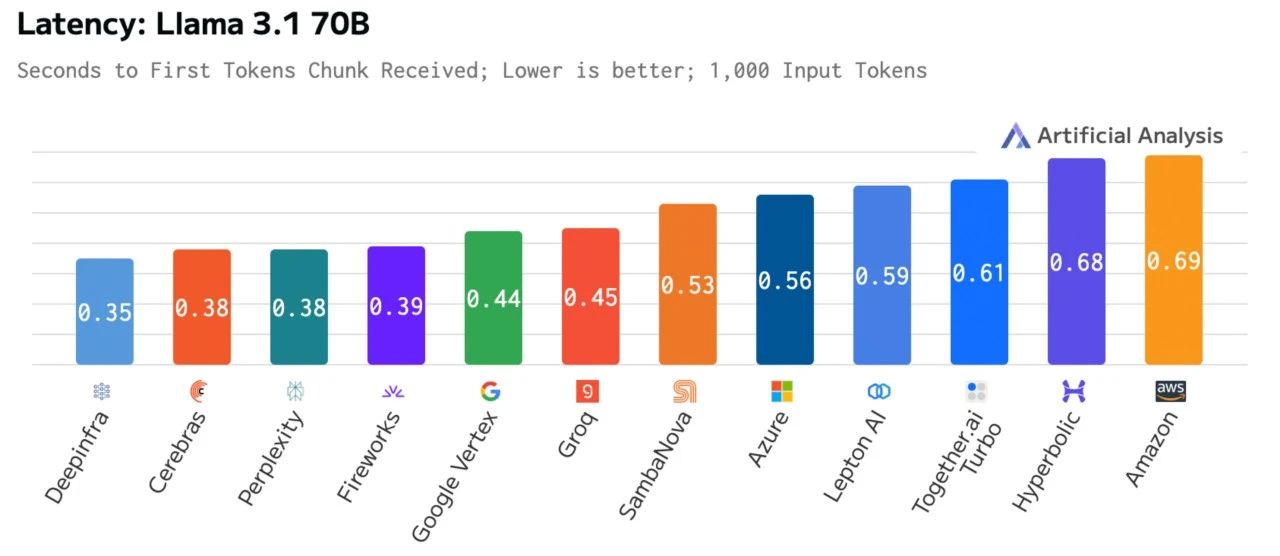
除了速度优势,Cerebras 在首个 token 的延迟方面也表现优异(首个 token 对于实时应用同样至关重要)。虽然在首个 token 延迟中没能拿到第一,但排名第二的成绩也足够优秀,显示出晶圆级集成解决方案相对于复杂网络解决方案的优势。
图源:Cerebras
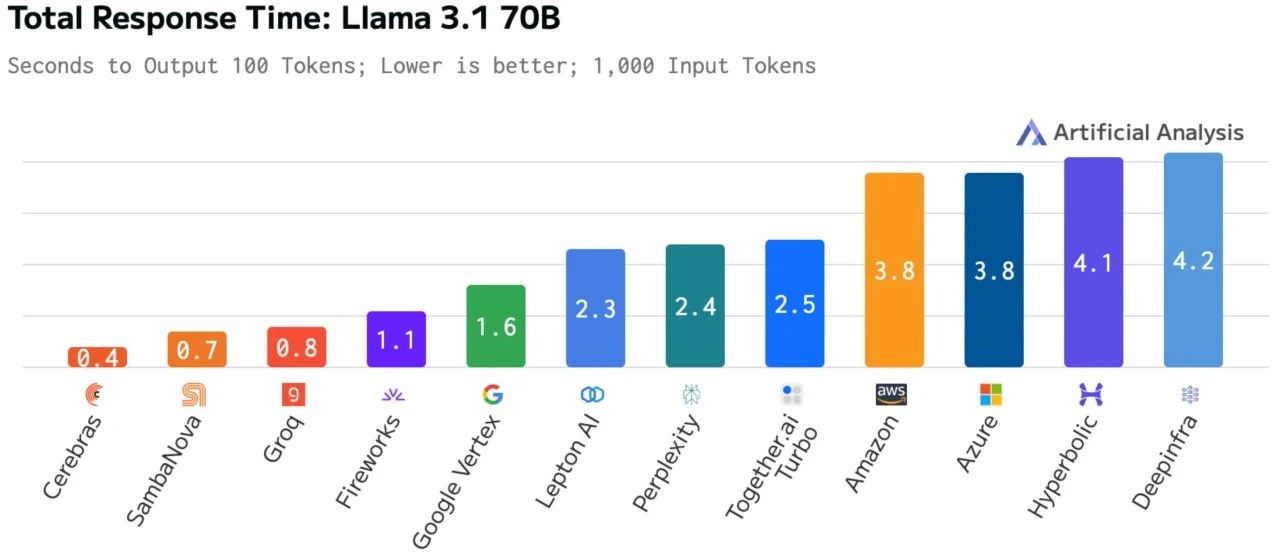
顶级的推理速度加上不俗的首个 token 延迟,让 Cerebras 的总响应时间仅有 0.4 秒(衡量输入和输出的完整循环),而基于 GPU 的解决方案则需要 1.1 到 4.2 秒,这也意味着 Cerebras 可以实现最高约 10 倍的推理步骤而不增加响应时间。
如今大家在看到各种 AI 产品对比、榜单排名时,都会留个心眼,无论官方怎么“吹捧”他的的产品,官方通常只会放出对他们自己有利的信息,最终还得看实际效果。Cerebras 为了让大家打消这样的疑虑,本次放出的所有对比图表全都是由权威的第三方基准测试机构 Artificial Analysis 亲自检验后得出的,没有任何虚假或不实信息。
看完枯燥的图表,我们不妨再来看看 Cerebras 实际的推理速度到底有多快。以生成一篇约 3000 字左右的文章为例,Cerebras 可以说就是一瞬间完成了全部内容生成,中间没有任何等待时间。
如果将 Cerebras 与 AWS 或 Azure 云服务上跑的 GPU 方案对比,差距更是十分显著(左边为 Cerebras)。
在同样的提示词下,左边生成完全部内容时,右边才刚生成完一段话。
如文章前面所说,Cerebras 刚推出 WSE-3 时运行 Llama 3.1 70B 模型测试出来的推理速度约为 450 tokens/s,当时能有这么快的速度全凭 WSE-3 AI 芯片的硬件实力。此次他们并没有死磕 AI 芯片,而是从内核、软件栈和 ML 等多个方面进行了优化,从而大大提高 Cerebras Inference 的利用率和实际性能。
首先 Cerebras 优化了矩阵乘法(MatMul),通过将大矩阵分成小块(分块),可以减少内存访问次数,提高缓存命中率。再将矩阵乘法的任务分配给多个处理器核心,可以同时进行多个计算,从而加速整个计算过程。
其次,他们还优化了 reduce/broadcast。在 AI 软件栈中,reduce 和 broadcast 是两种重要的集体通信操作,通常用于分布式计算和并行处理中。其中 reduce 操作会将所有参与通信的进程中的数据进行某种预定义的数值操作(如求和、最大值、最小值等),并将结果返回给指定的根进程。而 broadcast 操作则是将一个进程的数据发送到所有其他进程。reduce 和 broadcast 可以组合使用,这种组合操作可以简化代码并提高效率。
不过,要说本次更新中最重要的创新之处还是引入了推测解码技术,这是一种双模型协同技术,它同时使用小模型和大模型,小模型快速预测可能的输出,然后大模型验证和精确化结果。整个工作流程大概是:小模型快速生成候选结果 - 大模型并行验证多个候选 - 选择最优结果输出。这个技术可以减少等待时间、提高吞吐量,并保持输出质量。这也可以维持 16 位原始权重,模型输出精度保持不变。
不是期货,现在就能用
AI 公司为了保持热度、关注度,以及出于吸引投资等目的,时不时就会推出一些“重磅产品”,但这些产品从发布到实际能用上,中间可能会有半年、一年、甚至更长时间的等待。就比如 OpenAI 在今年 2 月发布的 Sora 视频生成模型,至今都没有正式推出,官方后续也没公布更多新消息,公众也无从得知目前这个模型的开发进度。
而 Cerebras Inference 更加实际一些,不是期货,而且已经有公司开始使用这一高速推理能力,并且在多个领域都展现出了实际价值。
全球知名的医药公司 GSK(葛兰素史克)正利用 Cerebras 开发创新 AI 应用,用于改进研究人员生产力和药物发现流程。AI 语音公司 LiveKit 则是使用 Cerebras 推理服务实现了包含语音转文本、模型推理和文本转语音的完整流程,处理速度超越传统解决方案。
Cerebras 接下来会继续优化软件和硬件功能,还会在未来几周内扩展模型选择、上下文长度和 API 功能。Cerebras 已向美国证券交易委员会提交招股说明书,一旦完成 IPO 就有望获得更多资金支持,进一步推动技术创新。








