
文/VR陀螺
腾讯ARC Lab又有新动作,这一次,生成式AI的焦点放在了3D生成上。
不久前,腾讯ARC Lab发布了一种新的AI模型“InstantMesh”,可以使用单张静态照片渲染3D对象。

图源:InstantMesh
根据腾讯研究院的说法,InstantMesh是一种用于从单个图像即时生成 3D 网格的前馈框架,能够在10秒内创建多样化的 3D 资产。通过网络图片实时转换,InstantMesh可以生成元宇宙中的OBJ格式3D模型。
实际体验下来,InstantMesh生成的模型质量见仁见智,但生成速度的确出乎意料。有用户在社交媒体上展示了利用InstantMesh预置图像生成3D模型的过程,并一连用“Super fast”“high quality”形容InstantMesh的输出效果。

图源:X
免去漫长的等待时间后,3D生成的效率这次真的提升了。
10秒内快速3D建模,还附赠模型六视图
InstantMesh的架构与Instant3D类似,都是由多视图扩散模型和稀疏视图重建模型组成。整个3D生成过程拆分为了两步:
首先,在给定输入图像后,使用多视图扩散模型生成 3D 一致的多视图图像;然后,利用稀疏视图大型重建模型直接预测3D网格,通过集成等值面提取模块(即 FlexiCubes)渲染 3D 几何形状,并将深度和法线等几何监督直接应用于网格表示以增强结果。几秒钟内就可以完成建模。
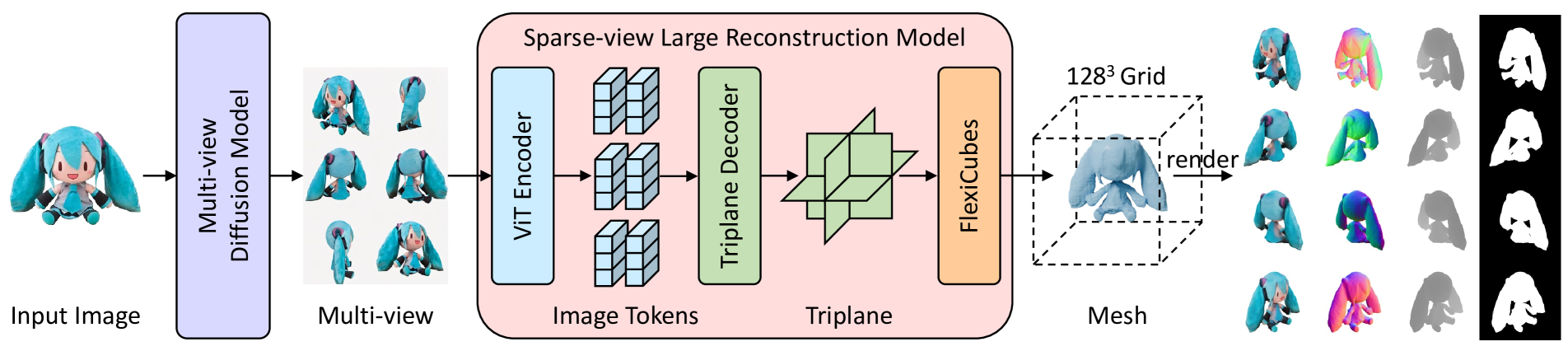
图源:InstantMesh
1、多视图扩散模型
面对单一输入图像,InstantMesh选择了将具有可靠的多视图一致性和定制的视点分布的Zero123++集成到框架之中,通过多视图扩散模型生成围绕对象调整的六个新视图,捕捉全方位视角。同时微调Zero123++来合成一致的白色背景图像,确保后期稀疏视图重建过程的稳定性。
2、大型稀疏视图重建模型
InstantMesh稀疏视图重建模型架构在Instant3D的基础上进行了修改和增强,训练数据集由Objaverse 80万个对象初始池中筛选出的大约 27 万个高质量实例组成。
在训练过程中,InstantMesh为了与 Zero123++ 的输出分辨率保持一致,将所有输入图像的大小都调整为 320×320,并将 Zero123++ 生成的 6 张图像作为重建模型的输入,以减轻多视图不一致问题。
最后,生成的多视图图像进入基于Transformer的大型稀疏视图重建模型,进行精细化的3D网格重建。
.png)
图源:InstantMesh
而为了进一步提升3D模型的质量与逼真度,InstantMesh还引入了等值面提取模块FlexiCubes,可以直接作用于网格表示,将深度和法线等关键几何信息融入重建过程,犹如为3D模型披上了一件质地细腻、纹理丰富的外衣。得益于此,InstantMesh生成的模型在视觉上更为细腻,在几何结构上更为精准,从内到外优化全面。
整个图像到3D的转化过程在短短10秒内即可完成,这无疑为创作者开启了全新的效率时代。
.png)
图源:InstantMesh
无论是专业设计师寻求快速迭代设计方案,还是普通用户渴望将生活瞬间转化为立体记忆,InstantMesh都能快速满足需求。更重要的是,其强大的泛化能力确保了在面对各类开放域图像时,都能生成合理且连贯的3D形状,打破了传统方法对特定数据集的依赖,实现了万物皆可3D的跨越。
腾讯开发团队声称实验结果表明InstantMesh的性能显着优于其他最新的图像转 3D 方法,那么,站在使用者的角度,InstantMesh的输出效果相比其他同类型的模型,是否真的做到了又快又好呢?
新的家具建模神器
InstantMesh的生成速度有多快呢,实测从照片导入到最终的模型生成总用时不超过50秒,建模过程则基本维持在10秒左右。
对于模型质量,InstantMesh声称其生成的 3D 网格呈现出更加合理的几何形状和外观。
实际使用下来发现,InstantMesh生成的模型具有完成清晰的表面,并且结构完整,这一点在生成家具等物体时尤为明显。
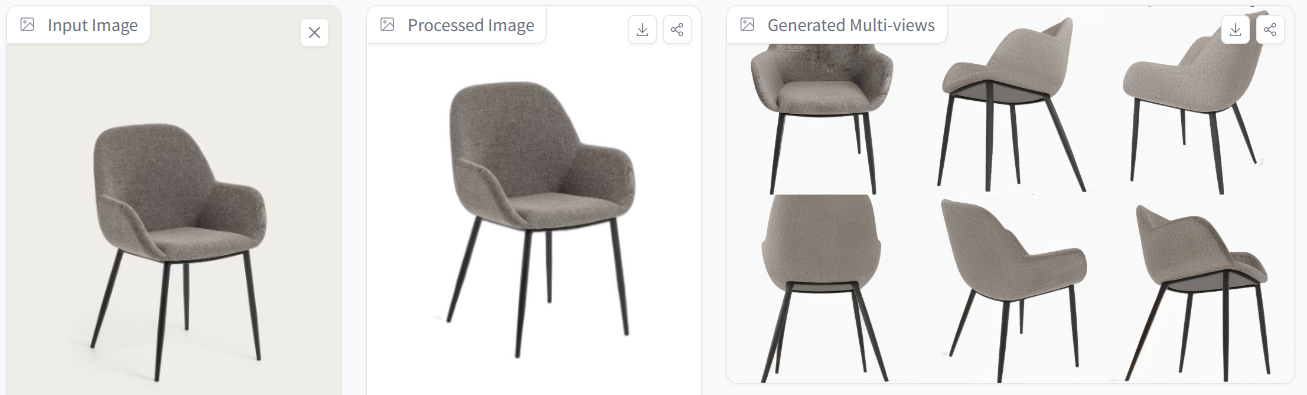

可以看到,生成的六视图以及最终模型不仅完美复现了图片视角的椅子材质结构形态,甚至连图片中不可见的椅面连接处结构也复现得合理且准确。
而当图片中出现两个以上物体时,InstantMesh不仅能复现椅子和桌子的不同形态,甚至连二者的位置关系也完全一致。


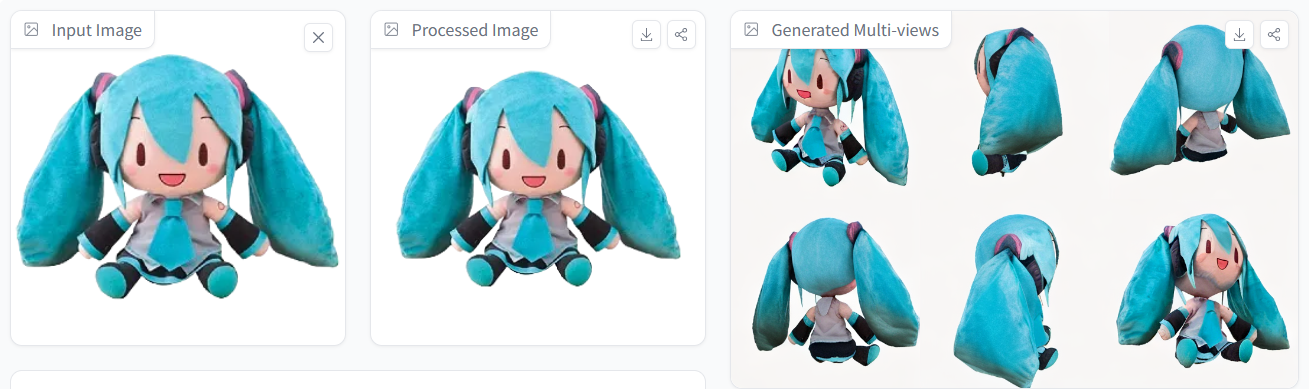
同样的,在生成手办、玩偶等虚拟形象的3D模型时,InstantMesh的表现也十分出色。
生成的3D模型几乎已经可以看做是图片内容的一比一手办了,无论是在色彩、结构还是体积感上都处理得已经接近商用水准。只不过还是有瑕疵存在,在识别玩偶图像中衣领部分时,模型似乎不知道如何呈现衣领部分,而是简单的将其去除,导致玩偶3D模型看起来脖子过长。


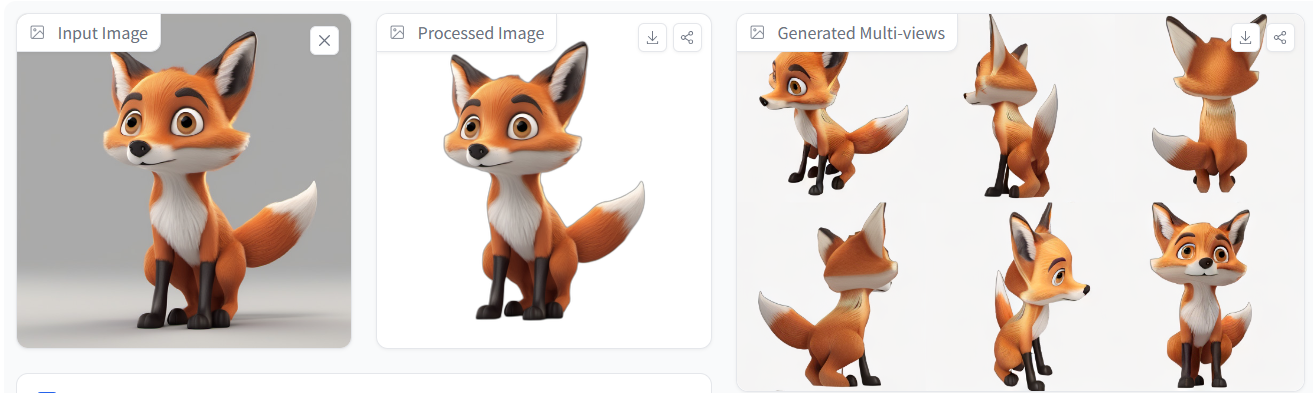


而在处理动物等现实生物的图像时,InstantMesh就开始显得力不从心了。
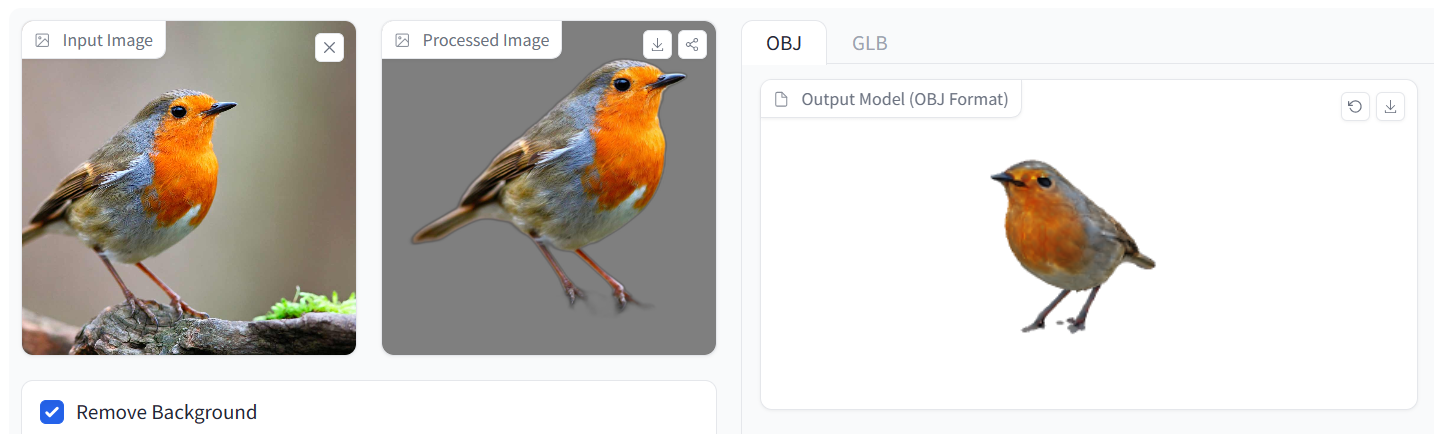
可以看到,在处理几何形状简单的动物形象(比如下图的鸟)时,InstantMesh水平仍旧在线,对于图片整体十分还原,唯一的不足出现在抠图上,导致模型腿部缺失,为3D建模拖了后腿。


而面对更加复杂的动物图像,InstantMesh虽然尽力还原除了模型的大概,但也出现了脸部细节缺失、背部材质缺失等不足。
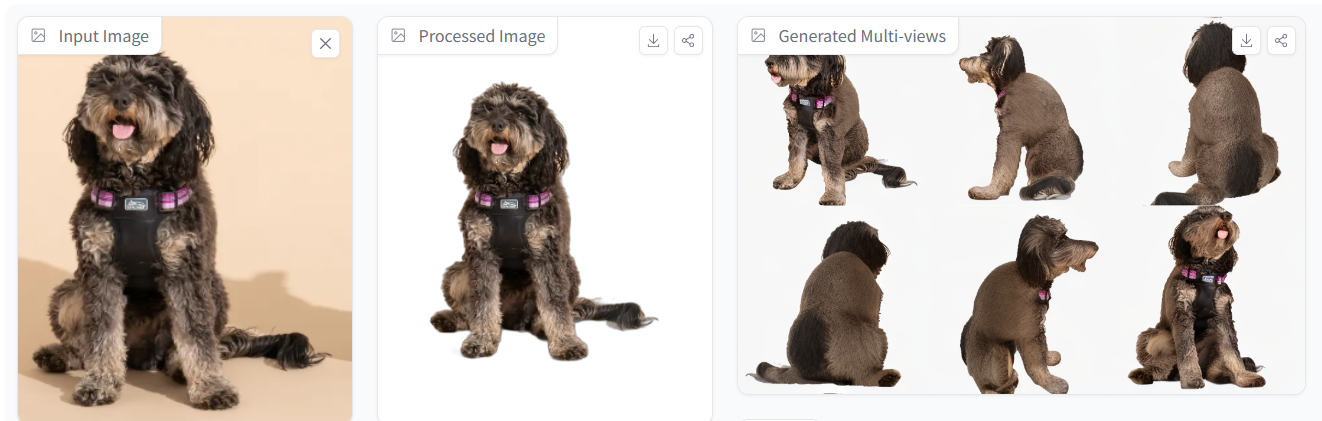

甚至,在面对连人类都会疑惑的“奇怪动物”时,InstantMesh同样也无从下手,当然,这一点无法苛责InstantMesh,毕竟目前的AI还无法向人类这样理解世界,至少在图片视角上,InstantMesh已经做到了还原,也算是合格了。


在论文中,InstantMesh不仅展示了自身的能力,还与TripoSR、LGM等类似的生成模型作了效果对比,称“TripoSR结果令人满意但缺乏想象力”“LGM等具有想象力但明显多视图不一致”。
那么,在同样的输入下,TripoSR和LGM的实际表现如何?
可以看到,TripoSR生成模型的质量在细节把控上优于InstantMesh,但相比之下,TripoSR对于体积感的把握并没有能够胜过InstantMesh,生成的企鹅形象未能像图片展示的一样饱满,从侧面看仿佛被砍了一刀。



而LGM生成的模型完美呈现了图片中没有展示的部分,且模型材质、形态控制出色,不足之处在于模型出现了轻微的重影,且在尾巴、后腿部分出现了不必要的模型粘连增生。


可以说,至少在生成模型的结果以及模型的可用程度上,InstantMesh已经达到了TripoSR的水准,并略优于LGM,并且由于生成的时间被压缩至10秒左右,大大加速了建模效率。
但同时,受制于输出过程中的分辨率控制,InstantMesh输出的图像在清晰度上明显遇到了瓶颈,虽然研发团队有意在未来的工作中解决这一限制,但即使解决了清晰度问题,由于客观存在的多视图不一致、细节建模问题,InstantMesh的建模效果离商用也还存在着一定差距。
至少目前来看,InstantMesh的应用场景更多可能还是在游戏3D资产等对建模精细度要求不高的领域上。当然,作为新一代的家具建模神器,在电商领域未来或许也能有InstantMesh的一席之地。
在苹果Vision Pro推出后,电商平台百思买 (Best Buy)、淘宝等都宣布了相关原生应用上线计划。
.png)
图源:百思买
从百思买已经公布的电商购物应用《Best Buy Envision》来看,用户在购买之前就可以在Vision Pro界面中浏览产品的3D模型外观,这意味着一款拥有数以万计商品的购物软件的背后有着同样数量级的3D资产需求,而电商产品的迭代速度之快又要求企业能以速度更快、成本更低的方式完成商品建模,这使得以InstantMesh为代表的AI建模未来有机会成为电商人的标配工具。
3D生成的终点不是场景建模
InstantMesh还在努力,但现在的3D生成技术已经不满足于纯粹的场景物体建模了,时下热门的数字人行业是更大的市场。
.png)
韩国数字人女团(图源:PULSE9)
3D生成技术在数字人领域的应用前景更多体现在超写实3D数字人建模上。
根据上海交通大学人工智能研究所的一篇论文显示,AI主要通过数据驱动的方式学习真实的数据分布、对数据分布进行采样以生成新的样本表示,并对数据表示进行渲染从而打造出高度真实的三维数字人。
而在3D数字人模型的表示方式上,常见的表示方式可以分为显式表示和隐式表示两种形式。其中, 显式表示一般直接给出满足条件的所有元素的集合,如点云包含三维空间中点的位置,多边形网格则包含顶点位置及其连接关系等信息。

图源:上海交通大学智能研究所
这一方法通常被应用在游戏、影视制作等工业应用中,优点在于传统的渲染管线已经能对其进行高效处理,但缺点在于生成模型的精细程度会受到分辨率限制,在对数字人高拟真外表的要求下,模型细节的增加会造成模型复杂度的上升。
在分辨率的硬性要求下,隐式表示就要好用得多。仅仅需要符号距离函数、水平集等三维空间约束,隐式表示就能够使数字人模型突破空间分辨率的限制,此外,使用深度符号距离函数、神经辐射场等神经网络逼近隐式函数还能恢复出数字人的精细几何与纹理,相比显式表示更加灵活。
国内团队推出的文本指导的渐进式3D生成框架DreamFace就结合了视觉-语言模型、隐式扩散模型和基于物理的材质扩散技术,可以生成符合计算机图形制作标准的3D数字人形象。
DreamFace不仅支持基于文本提示的发型和颜色生成,生成的模型还具备动画能力,能够提供更细致的表情细节,并且能够精细地捕捉表演。

图源:DreamFace
而在国外,更有以谷歌DreamHuman为代表的的文字生成带动画3D数字角色技术。
DreamHuman将大型文本到图像合成模型、神经辐射场和统计人体模型连接到新的建模和优化框架中,使得生成具有高质量纹理和特定要求的动态3D人体模型成为可能。

图源:DreamHuman
经过完整的生成式三维数字人建模流程之后, 生成模型将学习到数字人的先验信息, 针对模型进行相应微调即可应用到下游任务。
特别是在数字人重建应用中,生成式数字人模型为重建任务提供了有效的先验约束,不仅有助于生成合理的重建结果,也减少了对于训练标签的要求,降低了重建成本。只需要从图像或视频中恢复人体和人脸的三维几何形状以及对应的外观信息, 就可以实现真人与虚拟数字人一对一的数字化映射。
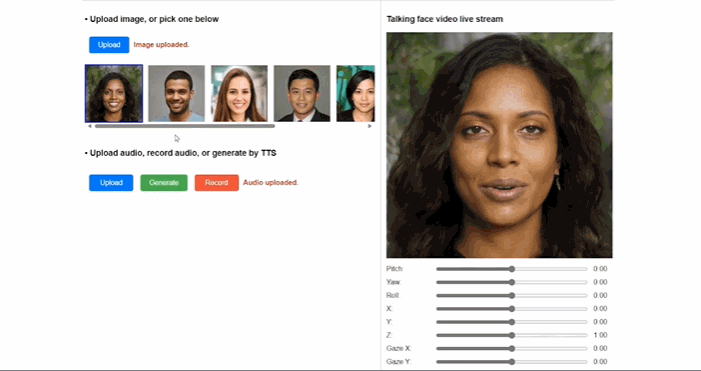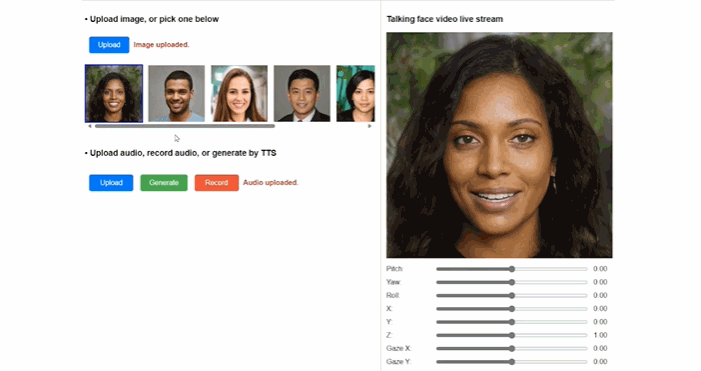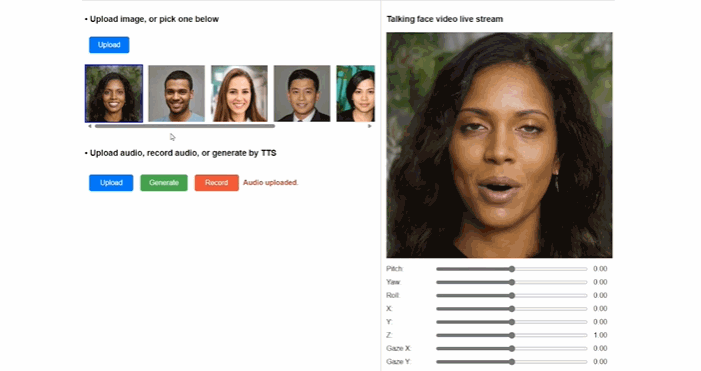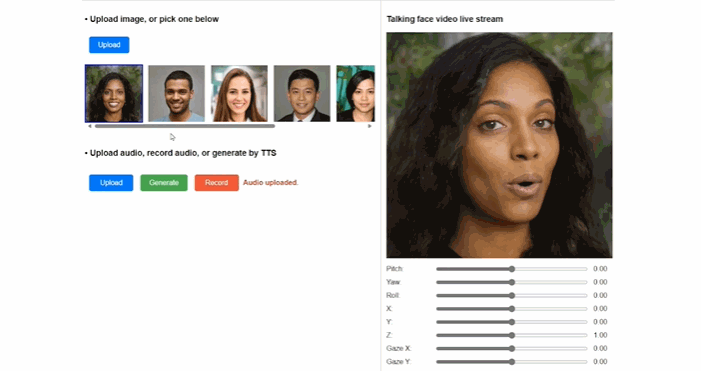
微软VASA-1(图源:微软)
代表应用既有从单张图片重建出目标人3D化身,并合成支持大姿态驱动的真实说话人视频的“单图 3D 说话人视频合成技术 (One-shot 3D Talking Face Generation)”,也有无需复杂采样和建模,只要一段几秒钟视频就能实现人物动作流畅的3D数字人合成工具“HUGS”(Human Gaussian Splats)。
其中,HUGS由苹果推出,是一种基于高斯函数的生成式AI技术,可以通过3D Gaussian Splatting(3DGS)和SMPL身体模型的融合创造出更加生动和真实的数字人物。

图源:HUGS
苹果对于数字人的研究并非一时兴起,而是有实际服务于产品的先例。在VisionPro上,用户就可以通过前置摄像头扫描面部信息,并基于机器学习技术和编码神经网络生成数字分身。当用户使用FaceTime通话时,数字分身还可以模仿用户的面部表情及手部动作。
可以预见,HUGS等技术的加入将使数字人形象无论是在二维平面屏幕还是三维元宇宙空间中都能演绎出生动逼真的表演。在AI的加持下,无论是智能助手、虚拟现实游戏,还是视频会议等多元场景,未来都将被“身手矫健”的虚拟人占据,为用户带来与现实无异的沉浸式互动体验。
而这也是InstantMesh们未来可以选择的方向。

图源:苹果
从游戏场景物体到虚拟人、虚拟世界,AI正在以复制现实世界为目标进步,在相关技术进一步完善与融合后,只需要一段文字、一张图片、一段视频,就可以构建一个场景真实、人物逼真的幻象空间。
我们有理由期待AI生成技术将以更快的步伐不断迭代,带来愈发惊艳的视觉享受与生活便利。虚拟现实的好日子还在后头。








