
编译/VR陀螺
近日,苹果公司展示了其新的人工智能系统GAUDI,该系统可以根据文本提示创建3D场景,是一款基于新一代NeRFs的生成式人工智能系统。
所谓的神经渲染能够将人工智能引入计算机图形。例如,Nvidia的人工智能研究人员正在展示如何从照片中创建3D物体,谷歌正在依靠神经辐射场(NeRFs)进行沉浸式视图或开发用于渲染人物的NeRFs。
到目前为止,NeRFs主要是作为3D模型和3D场景的一种神经存储介质,然后可以从不同的摄像机视角进行渲染,这种视角就是经常显示的摄像机在房间里或物体周围的移动方式。用于VR体验的 NeRFs 的初步实验也在进行中。
但是,如果NeRFs从不同角度逼真地呈现图像的能力可以用于生成式人工智能呢?像OpenAI的DALL-E 2或谷歌的Imagen和Parti这样的人工智能系统显示了可控生成式人工智能的潜力,但只适用于2D图像和图形。
谷歌在2021年底通过Dream Fields展示了3D人工智能的生成,这个人工智能系统结合了NeRFs生成3D视图的能力和OpenAI的CLIP评估图像内容的能力。其结果是,Dream Fields生成的NeRFs与文本描述相匹配。
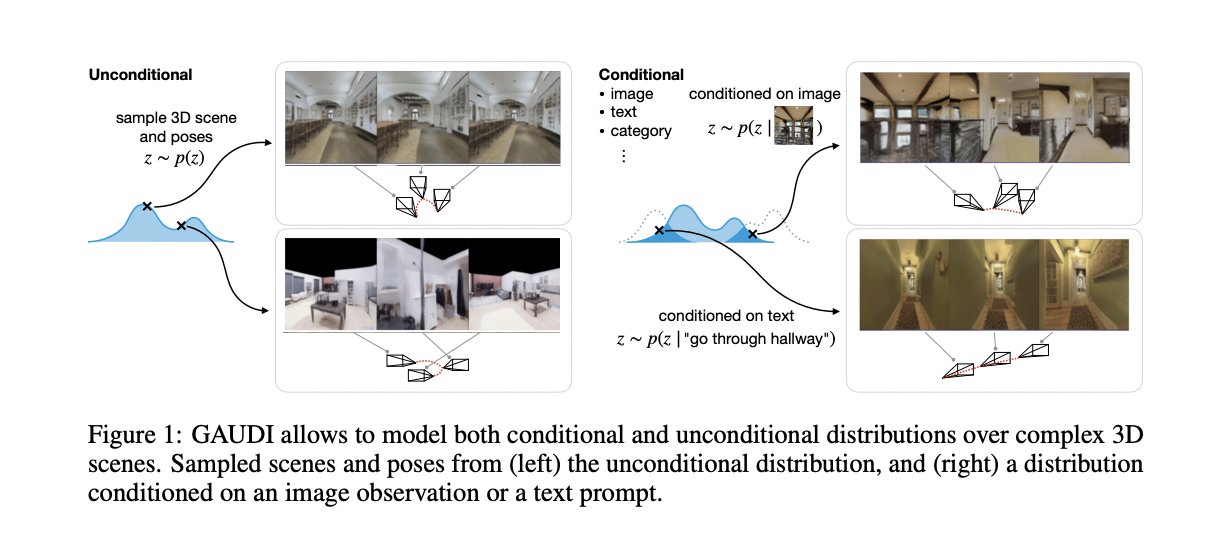
现在,苹果的人工智能团队正在推出GAUDI,这是一个用于生成沉浸式3D场景的神经架构,该人工智能系统可以根据文本提示创建3D场景。
 图源:苹果
图源:苹果
例如,虽然谷歌致力于用Dream Fields生成单个对象,但将生成式人工智能扩展到完全无约束的3D场景仍然是一个尚未解决的问题。
其中一个原因是可能的摄像机位置的限制。虽然对于单个对象来说,每一个可能的合理摄像机位置都可以被映射到一个圆顶上,但在3D场景中,这些摄像机位置会受到物体和墙壁等障碍物的限制。如果在场景生成过程中不考虑这些因素,生成的3D场景就无法使用。
苹果公司的GAUDI模型通过三个专门的网络来解决这个问题:一个摄像机姿势解码器对可能的摄像机位置进行预测,并确保输出是3D场景架构的有效位置。
 图源:苹果
图源:苹果
场景解码器可以通过一种3D画布的形式对场景进行预测,辐射场解码器在上面使用体积渲染方程绘制后续图像。
在四个不同的数据集的实验中(包括室内扫描数据集 ARKitScences),研究人员表明GAUDI可以重建学习的视图,并与现有方法的质量相匹配。
苹果公司还展示了GAUDI可以通过3D室内场景生成新的摄像机运动。生成可以是随机的,可以从图像开始,或由文本编码器的文本输入控制,例如,输入"穿过走廊 "或 "上楼梯"。
GAUDI生成的视频质量仍然很低,充满了伪影。但通过其人工智能系统,苹果正在为生成式人工智能系统奠定另一个基础,该系统可以渲染3D物体和场景。一个可能的应用是,为苹果的XR头显生成数字位置。
来源:mixed








